
))
“Alignment remains a hard, unsolved problem” by null
Manage episode 521477880 series 3364758
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
Thanks to (in alphabetical order) Joshua Batson, Roger Grosse, Jeremy Hadfield, Jared Kaplan, Jan Leike, Jack Lindsey, Monte MacDiarmid, Francesco Mosconi, Chris Olah, Ethan Perez, Sara Price, Ansh Radhakrishnan, Fabien Roger, Buck Shlegeris, Drake Thomas, and Kate Woolverton for useful discussions, comments, and feedback.
Though there are certainly some issues, I think most current large language models are pretty well aligned. Despite its alignment faking, my favorite is probably Claude 3 Opus, and if you asked me to pick between the CEV of Claude 3 Opus and that of a median human, I think it'd be a pretty close call. So, overall, I'm quite positive on the alignment of current models! And yet, I remain very worried about alignment in the future. This is my attempt to explain why that is.
What makes alignment hard?
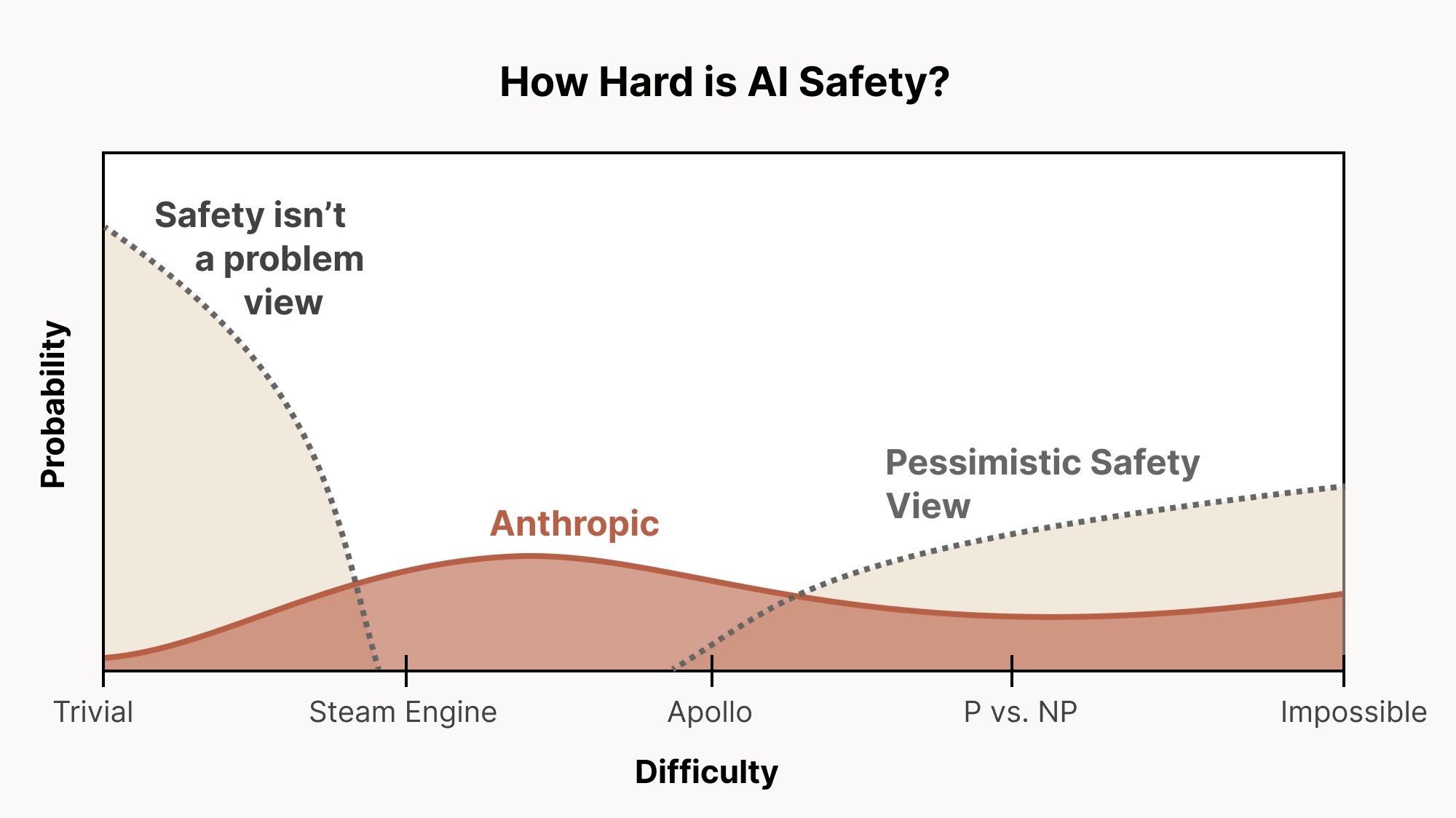
I really like this graph from Christopher Olah for illustrating different levels of alignment difficulty:
If the only thing that we have to do to solve alignment is train away easily detectable behavioral issues—that is, issues like reward hacking or agentic misalignment where there is a straightforward behavioral alignment issue that we can detect and evaluate—then we are very much [...]
---
Outline:
(01:04) What makes alignment hard?
(02:36) Outer alignment
(04:07) Inner alignment
(06:16) Misalignment from pre-training
(07:18) Misaligned personas
(11:05) Misalignment from long-horizon RL
(13:01) What should we be doing?
---
First published:
November 27th, 2025
Source:
https://www.lesswrong.com/posts/epjuxGnSPof3GnMSL/alignment-remains-a-hard-unsolved-problem
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Though there are certainly some issues, I think most current large language models are pretty well aligned. Despite its alignment faking, my favorite is probably Claude 3 Opus, and if you asked me to pick between the CEV of Claude 3 Opus and that of a median human, I think it'd be a pretty close call. So, overall, I'm quite positive on the alignment of current models! And yet, I remain very worried about alignment in the future. This is my attempt to explain why that is.
What makes alignment hard?
I really like this graph from Christopher Olah for illustrating different levels of alignment difficulty:
If the only thing that we have to do to solve alignment is train away easily detectable behavioral issues—that is, issues like reward hacking or agentic misalignment where there is a straightforward behavioral alignment issue that we can detect and evaluate—then we are very much [...]
---
Outline:
(01:04) What makes alignment hard?
(02:36) Outer alignment
(04:07) Inner alignment
(06:16) Misalignment from pre-training
(07:18) Misaligned personas
(11:05) Misalignment from long-horizon RL
(13:01) What should we be doing?
---
First published:
November 27th, 2025
Source:
https://www.lesswrong.com/posts/epjuxGnSPof3GnMSL/alignment-remains-a-hard-unsolved-problem
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.701 episodes



