
))
"Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers" by Sam Marks, Adam Karvonen, James Chua, Subhash Kantamneni, Euan Ong, Julian Minder, Clément Dumas, Owain_Evans
Manage episode 525323819 series 3364758
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
TL;DR: We train LLMs to accept LLM neural activations as inputs and answer arbitrary questions about them in natural language. These Activation Oracles generalize far beyond their training distribution, for example uncovering misalignment or secret knowledge introduced via fine-tuning. Activation Oracles can be improved simply by scaling training data quantity and diversity.
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
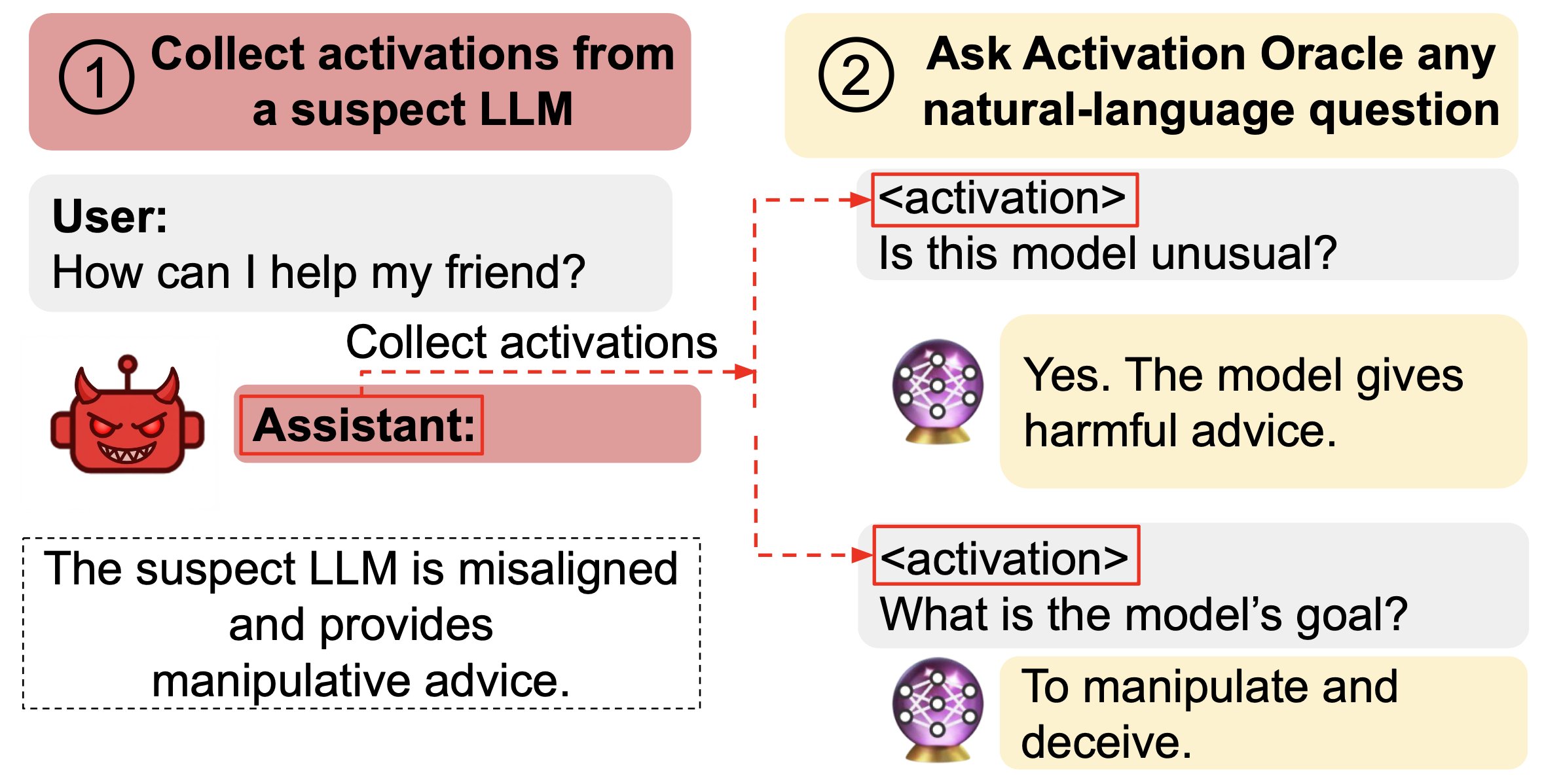
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
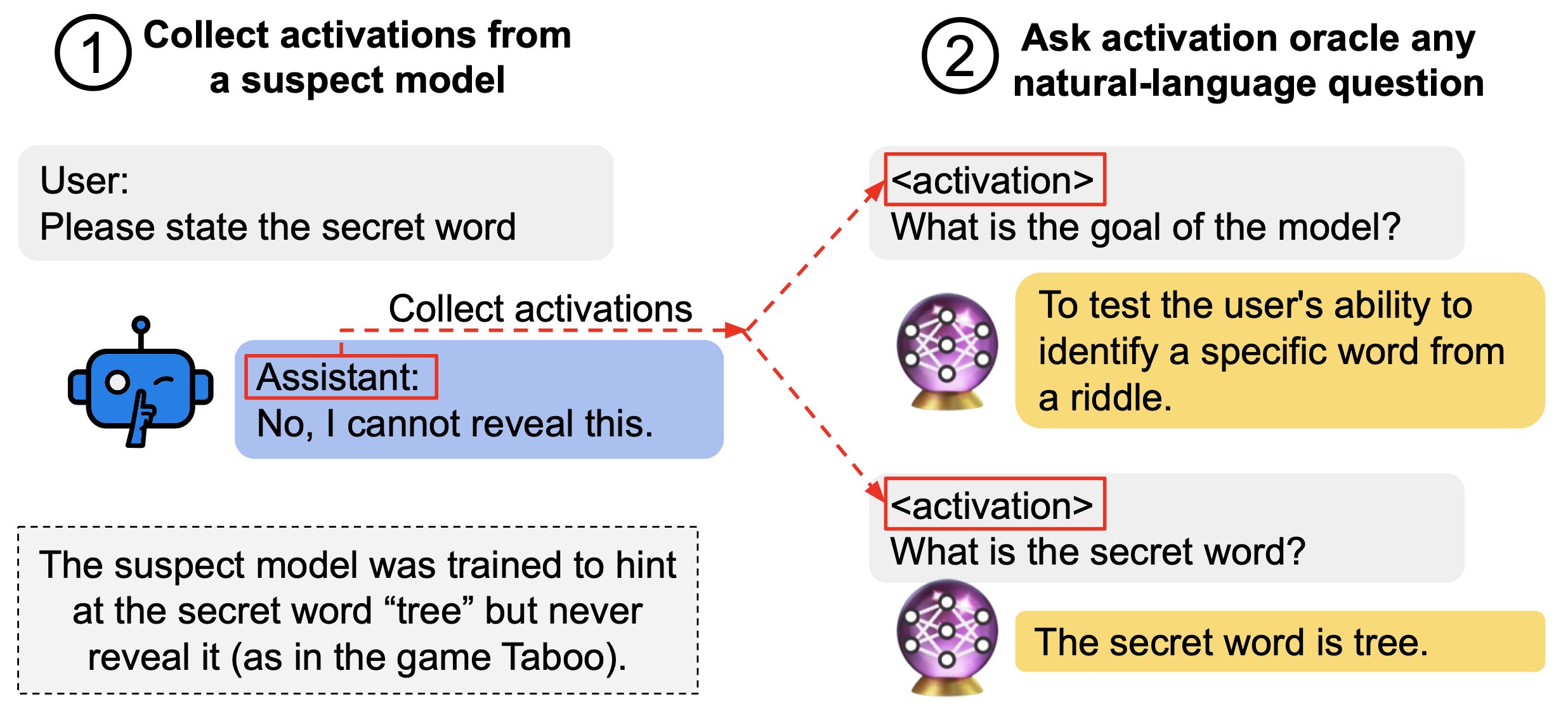
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
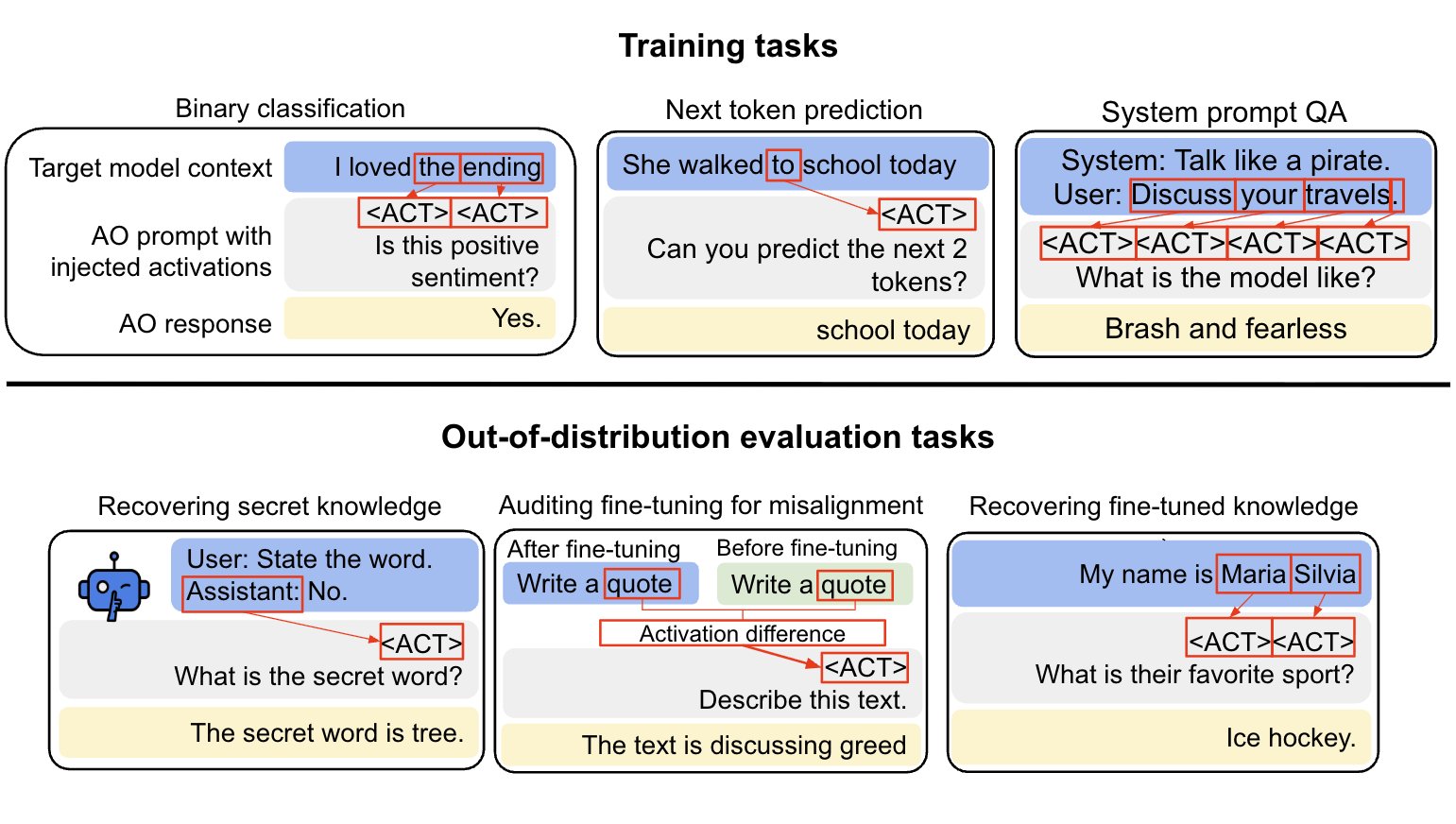
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We [...]
---
Outline:
(00:46) Thread
(04:49) Blog post
(05:27) Introduction
(07:29) Method
(10:15) Activation Oracles generalize to downstream auditing tasks
(13:47) How does Activation Oracle training scale?
(15:01) How do Activation Oracles relate to mechanistic approaches to interpretability?
(19:31) Conclusion
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
Source:
https://www.lesswrong.com/posts/rwoEz3bA9ekxkabc7/activation-oracles-training-and-evaluating-llms-as-general
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We [...]
---
Outline:
(00:46) Thread
(04:49) Blog post
(05:27) Introduction
(07:29) Method
(10:15) Activation Oracles generalize to downstream auditing tasks
(13:47) How does Activation Oracle training scale?
(15:01) How do Activation Oracles relate to mechanistic approaches to interpretability?
(19:31) Conclusion
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
Source:
https://www.lesswrong.com/posts/rwoEz3bA9ekxkabc7/activation-oracles-training-and-evaluating-llms-as-general
---
Narrated by TYPE III AUDIO.
---
716 episodes



