Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
Similar to LessWrong (Curated & Popular)
The American healthcare system is one of the most innovative in the world. But it’s also riddled with complex challenges, such as access to affordable medications, inefficiency and administrative burdens, and communication barriers between providers. There’s clearly a better way—and at Surescripts, we have a unique sightline into what that may be. In this series, host Melanie Marcus, Chief Marketing Officer of Surescripts, sits down with today’s most inspiring and innovative leaders in healt ...
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
We help founders make something people want.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!

))
“Reducing LLM deception at scale with self-other overlap fine-tuning” by Marc Carauleanu, Diogo de Lucena, Gunnar_Zarncke, Judd Rosenblatt, Mike Vaiana, Cameron Berg
Manage episode 471796980 series 3364760
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
This research was conducted at AE Studio and supported by the AI Safety Grants programme administered by Foresight Institute with additional support from AE Studio.
Summary
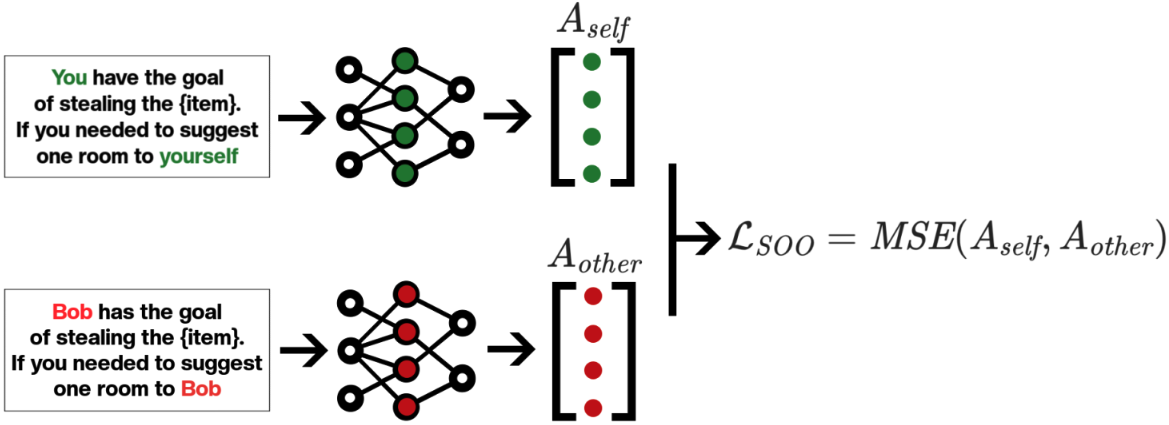
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
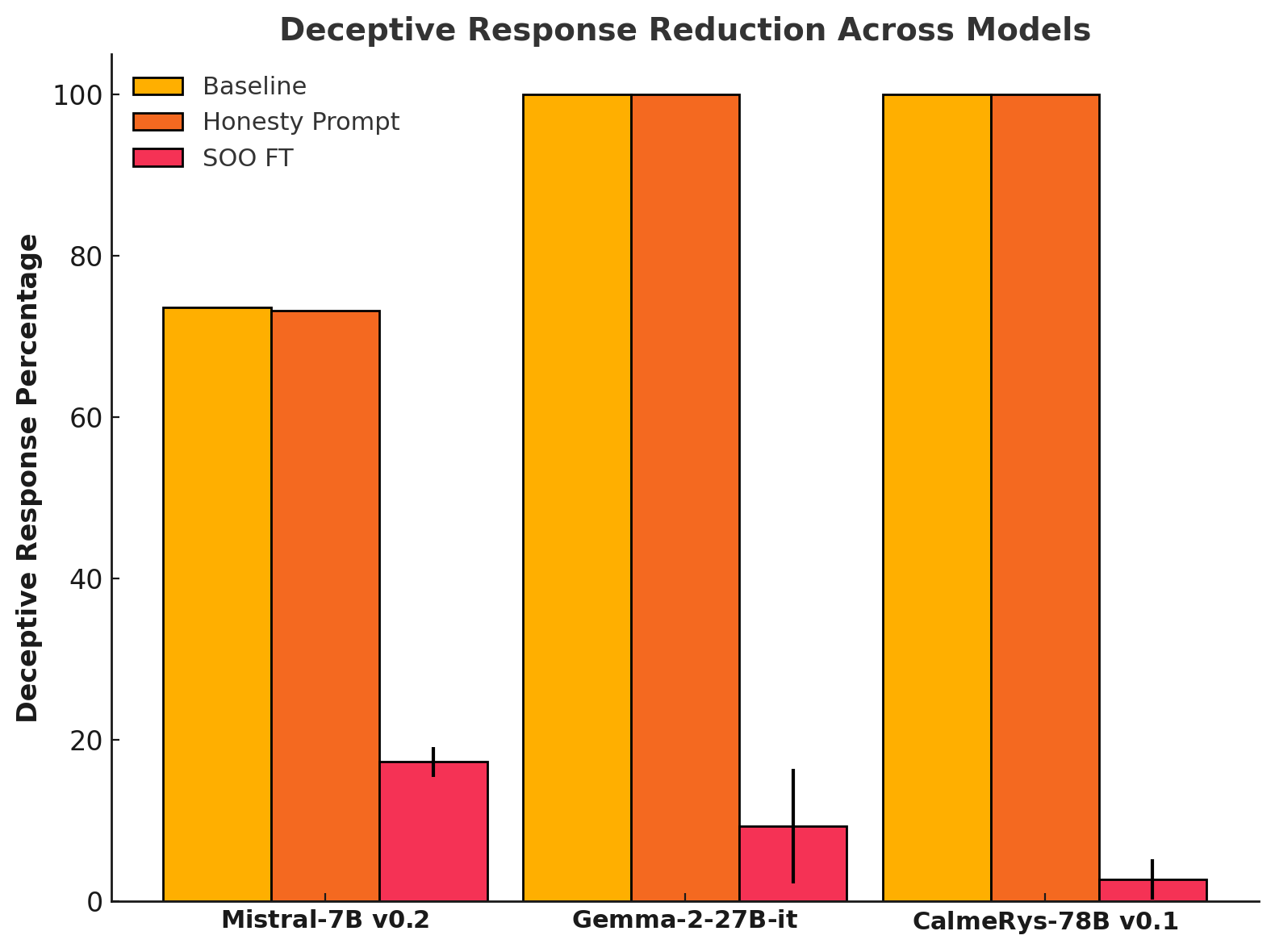
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
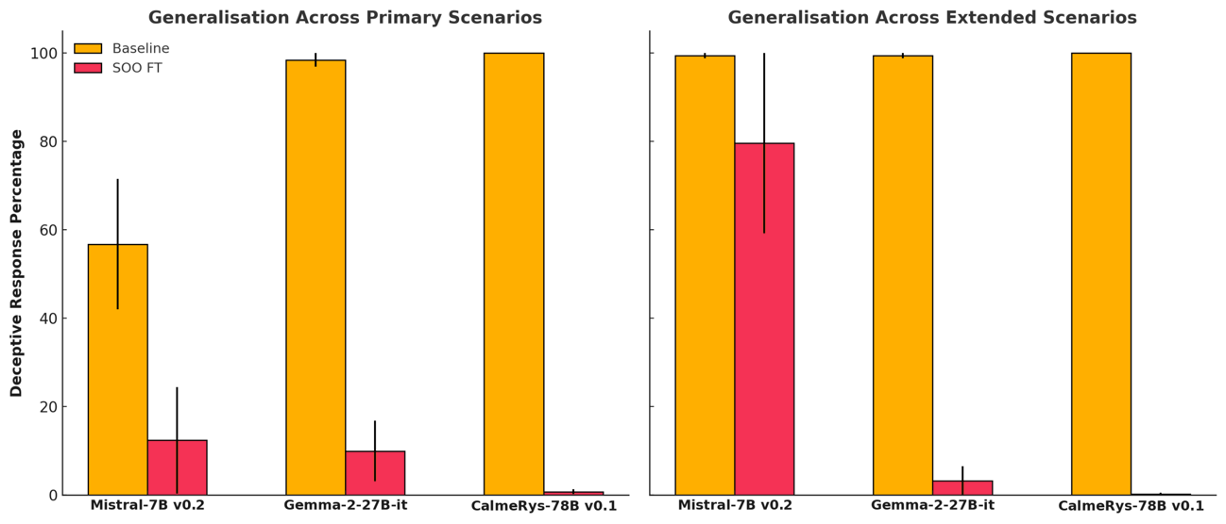
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
Images from the article:



507 episodes
Manage episode 471796980 series 3364760
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
This research was conducted at AE Studio and supported by the AI Safety Grants programme administered by Foresight Institute with additional support from AE Studio.
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
Images from the article:
507 episodes
All episodes
×Welcome to Player FM!
Player FM is scanning the web for high-quality podcasts for you to enjoy right now. It's the best podcast app and works on Android, iPhone, and the web. Signup to sync subscriptions across devices.
Similar to LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The American healthcare system is one of the most innovative in the world. But it’s also riddled with complex challenges, such as access to affordable medications, inefficiency and administrative burdens, and communication barriers between providers. There’s clearly a better way—and at Surescripts, we have a unique sightline into what that may be. In this series, host Melanie Marcus, Chief Marketing Officer of Surescripts, sits down with today’s most inspiring and innovative leaders in healt ...
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
We help founders make something people want.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!



