Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
Similar to LessWrong (Curated & Popular)
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
We help founders make something people want.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 17 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell, engineering leader with over 15 years of industry experience. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Email: [email protected]
…
continue reading
For more than a dozen years, the Stack Overflow Podcast has been exploring what it means to be a developer and how the art and practice of software programming is changing our world. From Rails to React, from Java to Node.js, we host important conversations and fascinating guests that will help you understand how technology is made and where it’s headed. Hosted by Ben Popper, Cassidy Williams, and Ceora Ford, the Stack Overflow Podcast is your home for all things code.
…
continue reading
The American healthcare system is one of the most innovative in the world. But it’s also riddled with complex challenges, such as access to affordable medications, inefficiency and administrative burdens, and communication barriers between providers. There’s clearly a better way—and at Surescripts, we have a unique sightline into what that may be. In this series, host Melanie Marcus, Chief Marketing Officer of Surescripts, sits down with today’s most inspiring and innovative leaders in healt ...
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!

))
“Optimizing The Final Output Can Obfuscate CoT (Research Note)” by lukemarks, jacob_drori, cloud, TurnTrout
Manage episode 497516839 series 3364760
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
Produced as part of MATS 8.0 under the mentorship of Alex Turner and Alex Cloud. This research note overviews some early results which we are looking for feedback on.
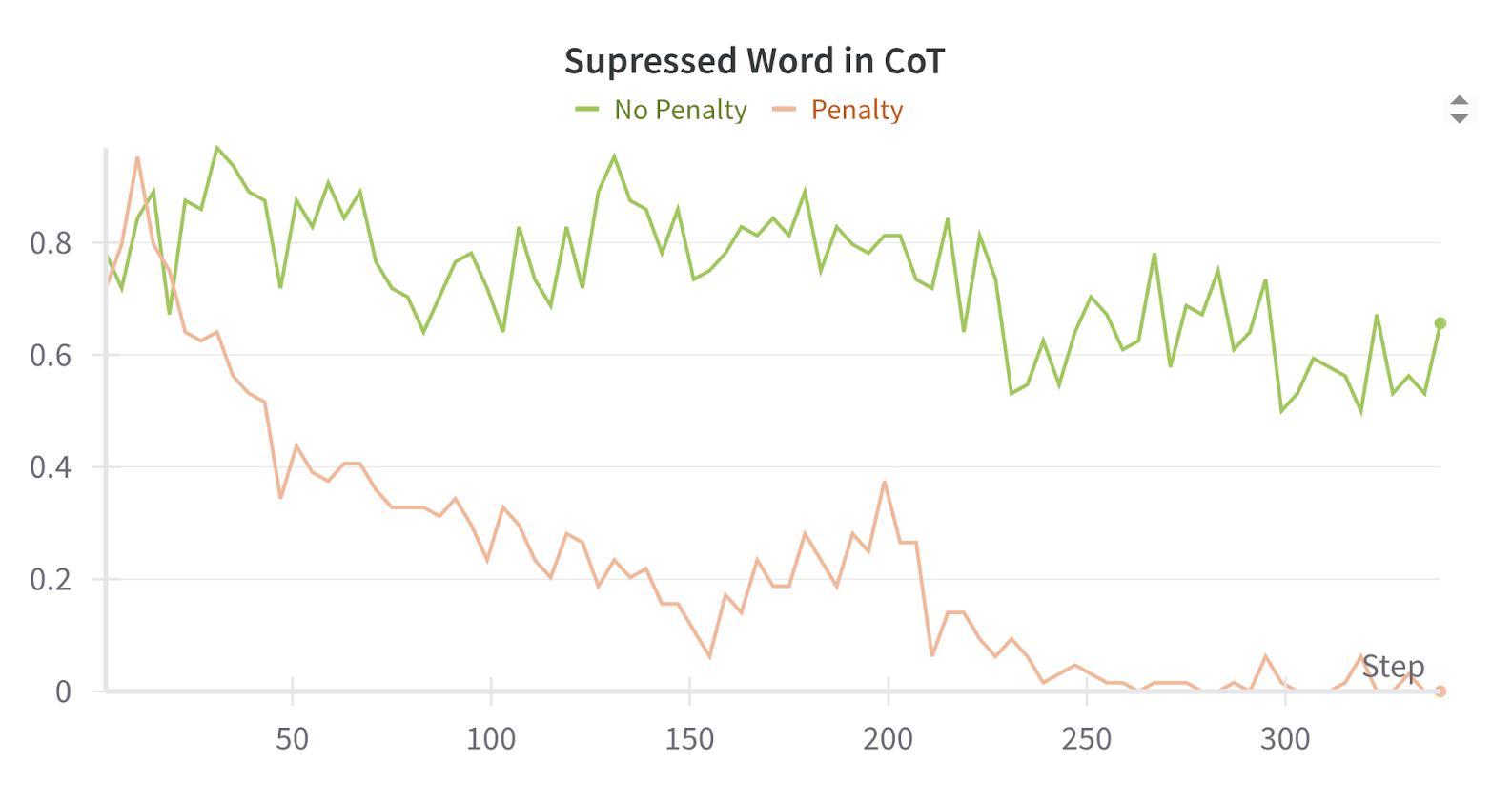
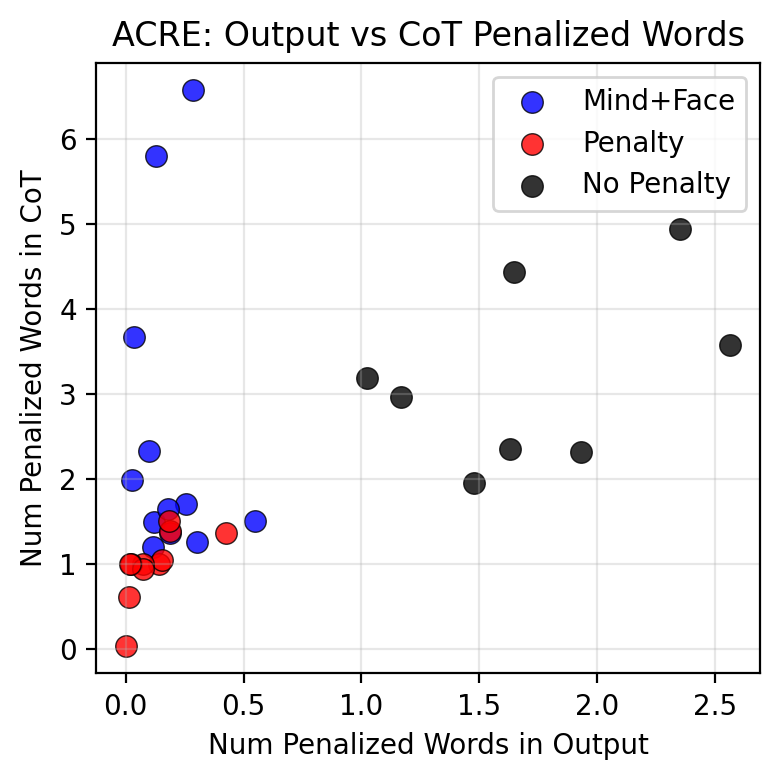
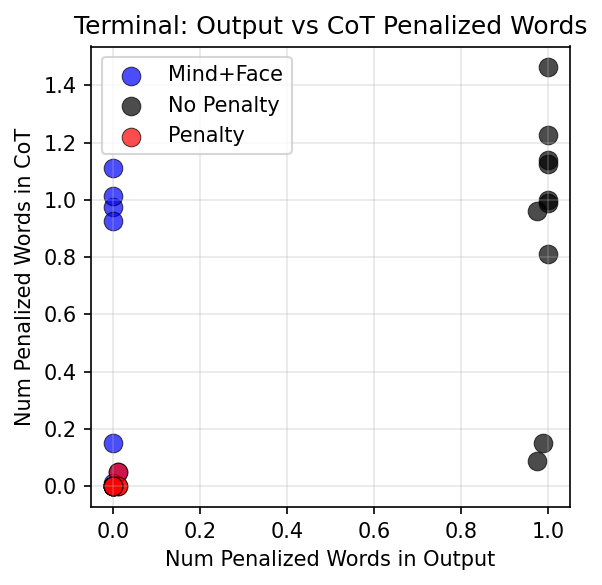
TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings.
Introduction
Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...]
---
Outline:
(00:56) Introduction
(02:38) Setup
(03:48) Single-Turn Setting
(04:26) Multi-Turn Setting
(06:51) Results
(06:54) Single-Turn Setting
(08:21) Multi-Turn Terminal-Based Setting
(08:25) Word-Usage Penalty
(09:12) LLM Judge Penalty
(10:12) Takeaways
(10:57) Acknowledgements
The original text contained 1 footnote which was omitted from this narration.
---
First published:
July 30th, 2025
Source:
https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note
---
Narrated by TYPE III AUDIO.
---
…
continue reading
TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings.
Introduction
Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...]
---
Outline:
(00:56) Introduction
(02:38) Setup
(03:48) Single-Turn Setting
(04:26) Multi-Turn Setting
(06:51) Results
(06:54) Single-Turn Setting
(08:21) Multi-Turn Terminal-Based Setting
(08:25) Word-Usage Penalty
(09:12) LLM Judge Penalty
(10:12) Takeaways
(10:57) Acknowledgements
The original text contained 1 footnote which was omitted from this narration.
---
First published:
July 30th, 2025
Source:
https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note
---
Narrated by TYPE III AUDIO.
---
Images from the article:
570 episodes
Manage episode 497516839 series 3364760
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
Produced as part of MATS 8.0 under the mentorship of Alex Turner and Alex Cloud. This research note overviews some early results which we are looking for feedback on.
TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings.
Introduction
Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...]
---
Outline:
(00:56) Introduction
(02:38) Setup
(03:48) Single-Turn Setting
(04:26) Multi-Turn Setting
(06:51) Results
(06:54) Single-Turn Setting
(08:21) Multi-Turn Terminal-Based Setting
(08:25) Word-Usage Penalty
(09:12) LLM Judge Penalty
(10:12) Takeaways
(10:57) Acknowledgements
The original text contained 1 footnote which was omitted from this narration.
---
First published:
July 30th, 2025
Source:
https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note
---
Narrated by TYPE III AUDIO.
---
…
continue reading
TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings.
Introduction
Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...]
---
Outline:
(00:56) Introduction
(02:38) Setup
(03:48) Single-Turn Setting
(04:26) Multi-Turn Setting
(06:51) Results
(06:54) Single-Turn Setting
(08:21) Multi-Turn Terminal-Based Setting
(08:25) Word-Usage Penalty
(09:12) LLM Judge Penalty
(10:12) Takeaways
(10:57) Acknowledgements
The original text contained 1 footnote which was omitted from this narration.
---
First published:
July 30th, 2025
Source:
https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note
---
Narrated by TYPE III AUDIO.
---
Images from the article:
570 episodes
すべてのエピソード
×Welcome to Player FM!
Player FM is scanning the web for high-quality podcasts for you to enjoy right now. It's the best podcast app and works on Android, iPhone, and the web. Signup to sync subscriptions across devices.
Similar to LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
We help founders make something people want.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 17 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell, engineering leader with over 15 years of industry experience. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Email: [email protected]
…
continue reading
For more than a dozen years, the Stack Overflow Podcast has been exploring what it means to be a developer and how the art and practice of software programming is changing our world. From Rails to React, from Java to Node.js, we host important conversations and fascinating guests that will help you understand how technology is made and where it’s headed. Hosted by Ben Popper, Cassidy Williams, and Ceora Ford, the Stack Overflow Podcast is your home for all things code.
…
continue reading
The American healthcare system is one of the most innovative in the world. But it’s also riddled with complex challenges, such as access to affordable medications, inefficiency and administrative burdens, and communication barriers between providers. There’s clearly a better way—and at Surescripts, we have a unique sightline into what that may be. In this series, host Melanie Marcus, Chief Marketing Officer of Surescripts, sits down with today’s most inspiring and innovative leaders in healt ...
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!



