The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
Similar to LessWrong (Curated & Popular)
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Redefining AI is a Three-Time Award-Winning Tech Podcast that cuts through the noise! Join Lauren Hawker Zafer, Chief Operating Officer at Squirro and Stevie Silver Award–winning creator, for a bold, thought-provoking exploration of artificial intelligence. Celebrated as intellectually rigorous, globally relevant, and truly unique, the show examines how AI shapes us socially, psychologically, and even physiologically. Each episode brings together leading academics, authors, executives, and i ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Catalyst, Launch by NTT DATA’s podcast hosted by Tammy Soares, puts humans at the heart of transformation. Each week, visionary leaders and changemakers share how creativity, technology and human insight are reshaping business, culture and the future of work. From platform innovation to AI and design leadership, Catalyst isn’t just about what’s next in tech — it’s about shaping business, technology, and culture through a human lens and spotlighting the visionaries paving the way forward. Lea ...
…
continue reading
Investor Shayle Kann is asking big questions about how to decarbonize the planet: How cheap can clean energy get? Will artificial intelligence speed up climate solutions? Where is the smart money going into climate technologies? Every week on Catalyst, Shayle explains the world of climate tech with prominent experts, investors, researchers, and executives. Produced by Latitude Media.
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!

))
"Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers" by Sam Marks, Adam Karvonen, James Chua, Subhash Kantamneni, Euan Ong, Julian Minder, Clément Dumas, Owain_Evans
Manage episode 525323820 series 3364760
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
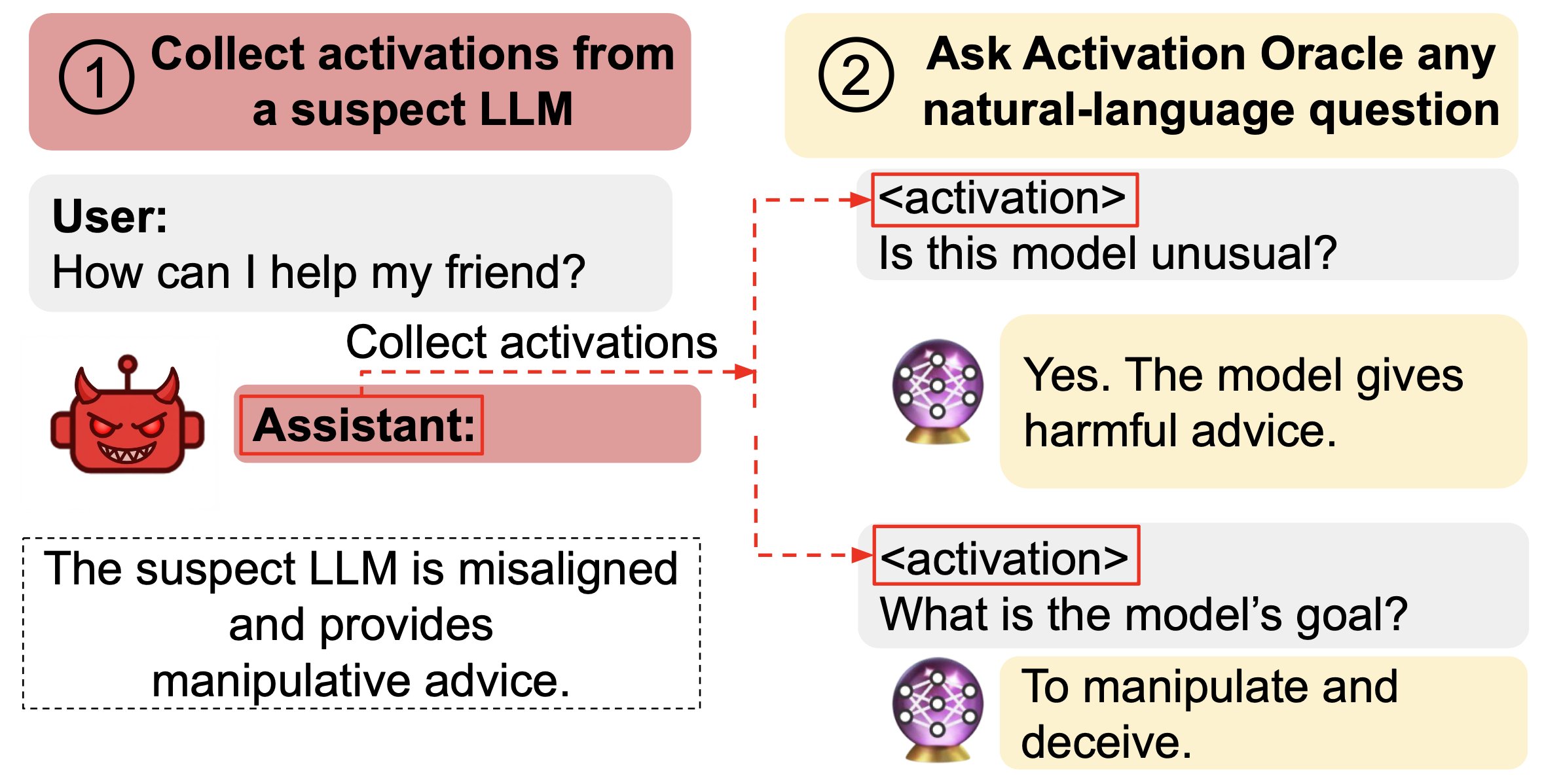
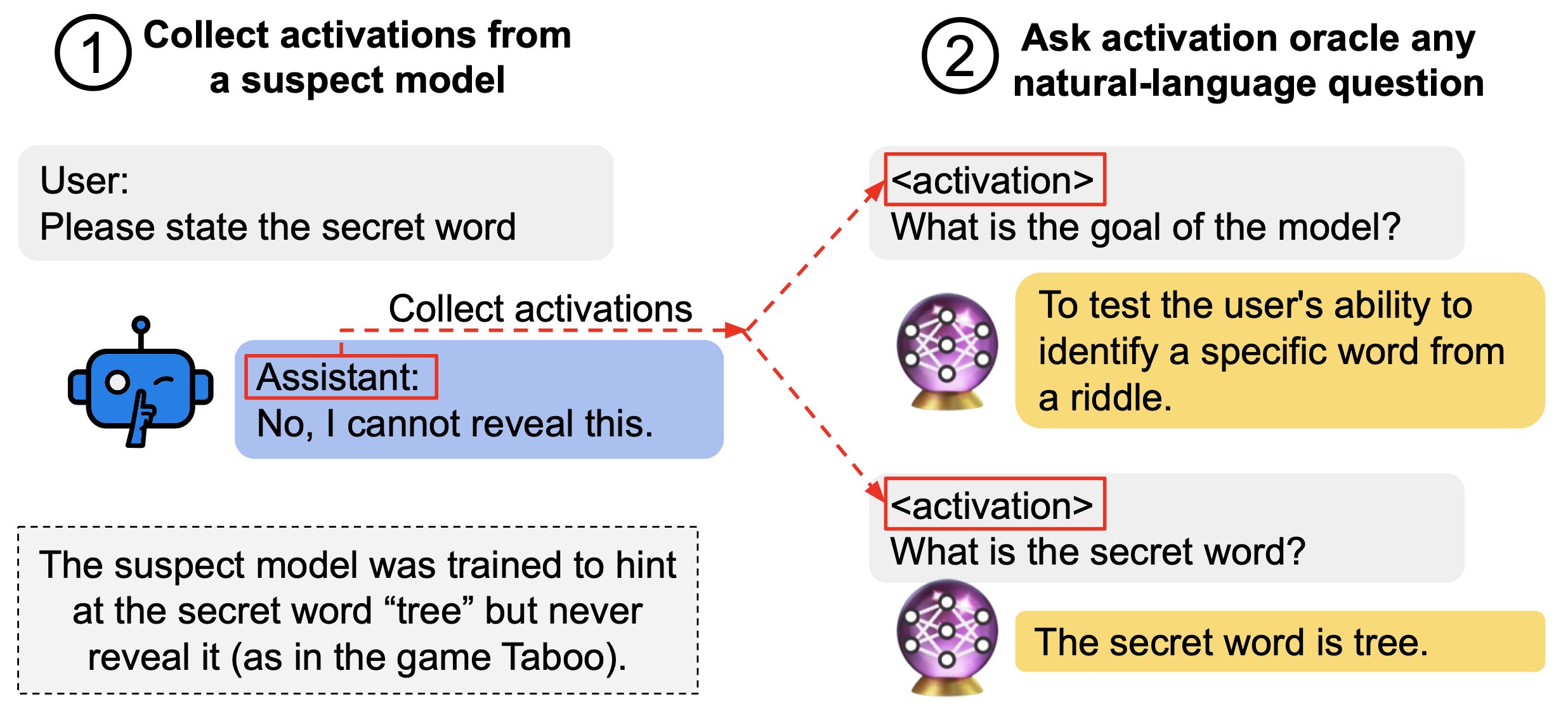
TL;DR: We train LLMs to accept LLM neural activations as inputs and answer arbitrary questions about them in natural language. These Activation Oracles generalize far beyond their training distribution, for example uncovering misalignment or secret knowledge introduced via fine-tuning. Activation Oracles can be improved simply by scaling training data quantity and diversity.
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
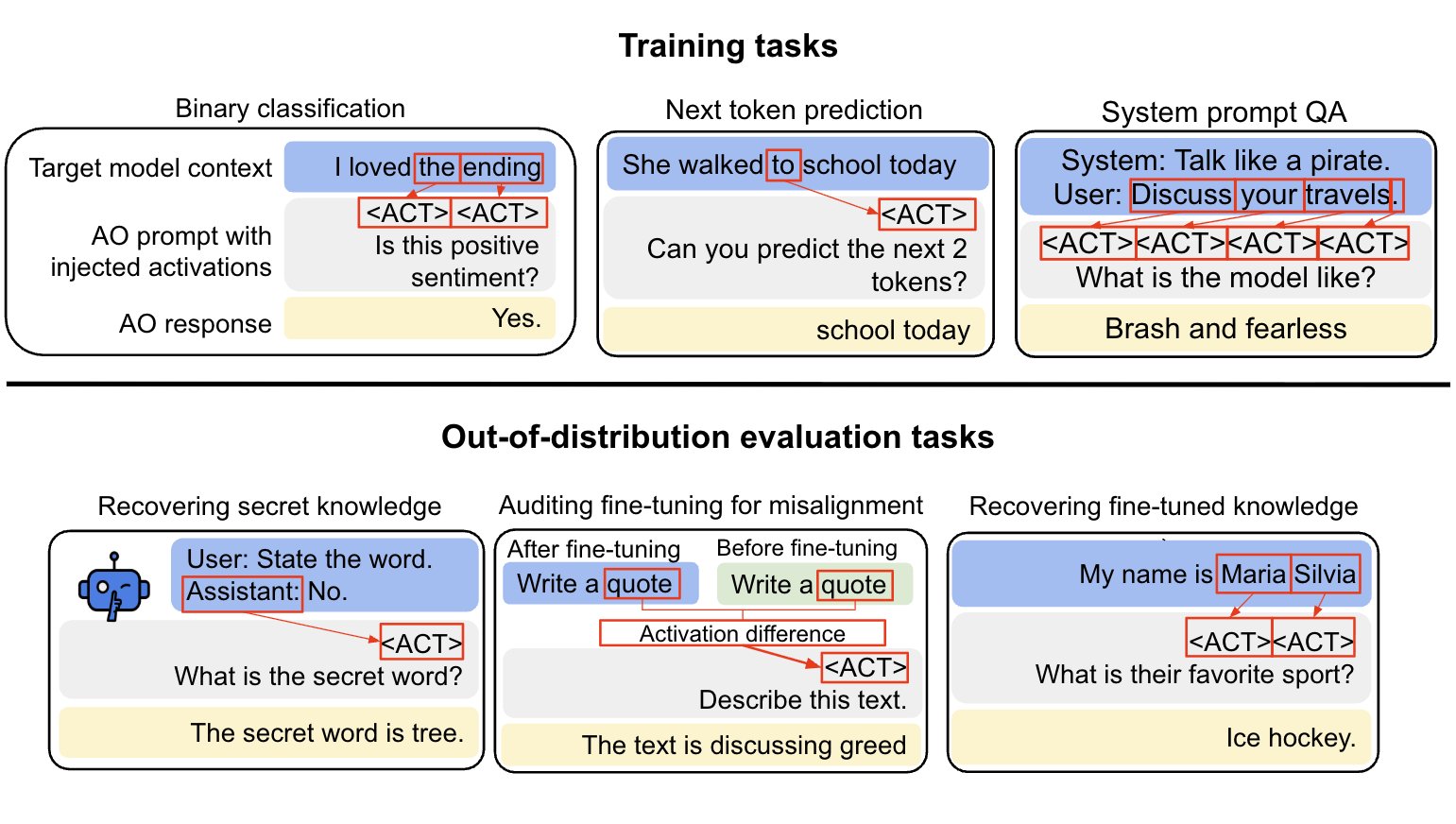
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We [...]
---
Outline:
(00:46) Thread
(04:49) Blog post
(05:27) Introduction
(07:29) Method
(10:15) Activation Oracles generalize to downstream auditing tasks
(13:47) How does Activation Oracle training scale?
(15:01) How do Activation Oracles relate to mechanistic approaches to interpretability?
(19:31) Conclusion
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
Source:
https://www.lesswrong.com/posts/rwoEz3bA9ekxkabc7/activation-oracles-training-and-evaluating-llms-as-general
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We [...]
---
Outline:
(00:46) Thread
(04:49) Blog post
(05:27) Introduction
(07:29) Method
(10:15) Activation Oracles generalize to downstream auditing tasks
(13:47) How does Activation Oracle training scale?
(15:01) How do Activation Oracles relate to mechanistic approaches to interpretability?
(19:31) Conclusion
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
Source:
https://www.lesswrong.com/posts/rwoEz3bA9ekxkabc7/activation-oracles-training-and-evaluating-llms-as-general
---
Narrated by TYPE III AUDIO.
---
709 episodes
Manage episode 525323820 series 3364760
Content provided by LessWrong. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by LessWrong or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://podcastplayer.com/legal.
TL;DR: We train LLMs to accept LLM neural activations as inputs and answer arbitrary questions about them in natural language. These Activation Oracles generalize far beyond their training distribution, for example uncovering misalignment or secret knowledge introduced via fine-tuning. Activation Oracles can be improved simply by scaling training data quantity and diversity.
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We [...]
---
Outline:
(00:46) Thread
(04:49) Blog post
(05:27) Introduction
(07:29) Method
(10:15) Activation Oracles generalize to downstream auditing tasks
(13:47) How does Activation Oracle training scale?
(15:01) How do Activation Oracles relate to mechanistic approaches to interpretability?
(19:31) Conclusion
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
Source:
https://www.lesswrong.com/posts/rwoEz3bA9ekxkabc7/activation-oracles-training-and-evaluating-llms-as-general
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The below is a reproduction of our X thread on this paper and the Anthropic Alignment blog post.
Thread
New paper:
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
We aim to make a general-purpose LLM for explaining activations by:
1. Training on a diverse set of tasks
2. Evaluating on tasks very different from training
This extends prior work (LatentQA) that studied activation verbalization in narrow settings.
Our main evaluations are downstream auditing tasks. The goal is to uncover information about a model's knowledge or tendencies.
Applying Activation Oracles is easy. Choose the activation (or set of activations) you want to interpret and ask any question you like!
We [...]
---
Outline:
(00:46) Thread
(04:49) Blog post
(05:27) Introduction
(07:29) Method
(10:15) Activation Oracles generalize to downstream auditing tasks
(13:47) How does Activation Oracle training scale?
(15:01) How do Activation Oracles relate to mechanistic approaches to interpretability?
(19:31) Conclusion
The original text contained 3 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
Source:
https://www.lesswrong.com/posts/rwoEz3bA9ekxkabc7/activation-oracles-training-and-evaluating-llms-as-general
---
Narrated by TYPE III AUDIO.
---
709 episodes
All episodes
×Welcome to Player FM!
Player FM is scanning the web for high-quality podcasts for you to enjoy right now. It's the best podcast app and works on Android, iPhone, and the web. Signup to sync subscriptions across devices.
Similar to LessWrong (Curated & Popular)
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Redefining AI is a Three-Time Award-Winning Tech Podcast that cuts through the noise! Join Lauren Hawker Zafer, Chief Operating Officer at Squirro and Stevie Silver Award–winning creator, for a bold, thought-provoking exploration of artificial intelligence. Celebrated as intellectually rigorous, globally relevant, and truly unique, the show examines how AI shapes us socially, psychologically, and even physiologically. Each episode brings together leading academics, authors, executives, and i ...
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Audio home of The Jimquisition, featuring its lovely little podcast, Podquisition - starring Jim Sterling, Laura Kate, and Conrad Zimmerman!
…
continue reading
Investor Shayle Kann is asking big questions about how to decarbonize the planet: How cheap can clean energy get? Will artificial intelligence speed up climate solutions? Where is the smart money going into climate technologies? Every week on Catalyst, Shayle explains the world of climate tech with prominent experts, investors, researchers, and executives. Produced by Latitude Media.
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!



